Section Three
Clustering
Modeling without Feature Selection
In this project, two models were selected, namely DBSCAN and K-Means, to be tested without prior feature selection. The evaluation results using silhouette score were 0.590 (K-Means) and 0.22 (DBSCAN).
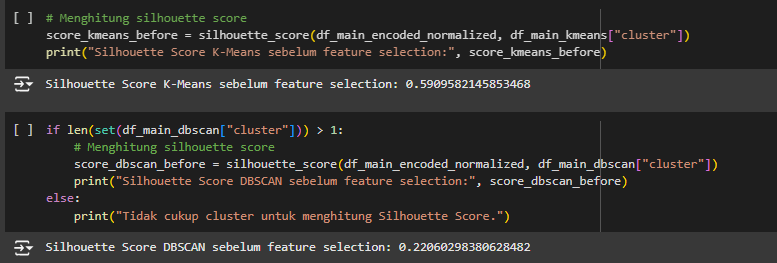
The K-Means model shows good performance, but the issue is that it uses too many features, which can make interpreting the clustering results more difficult. It means the features selection was needed.
Modeling with Feature Selection
To solve the issue, Correlation Matrix was used to show which features has the most significant correlation to each other.
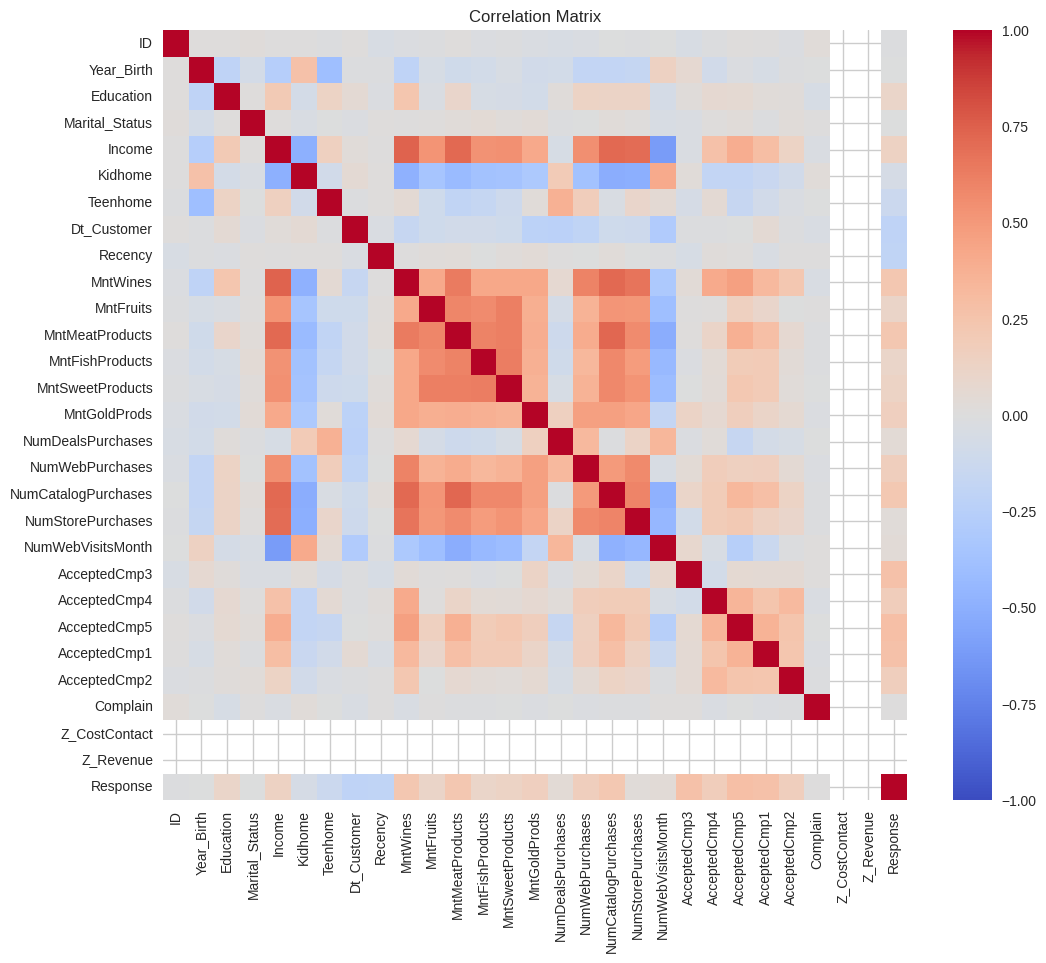
Based on the correlation matrix, 16 features are considered, with 5 or 6 to be selected for model training. Here are the 16 features:
- Year_Birth
- Education
- Income
- MntWines
- MntFruits
- MntMeatProducts
- MntFishProducts
- MntSweetProducts
- MntGoldProds
- NumWebPurchases
- NumCatalogPurchases
- NumStorePurchases
- Kidhome
- NumWebVisitsMonth
- Marital_Status
- Response
Since we select 5 or 6 out of 16, It will take so much times if we select them manually.
Mathematically, if we selected 5 out of 16 features, we will need C_16^5=16!/(16-5)!5!=4368 trial to find the best 5 features (globally optimal) and C_16^6=16!/(16-6)!6!=8008 trial for the best 6 features selection. From here, the grid search was used to find the best 5 or 6 features, since 8008 trial was considered as ‘not a really big number’ to do the grid search.
The grid search applied to K-Means clustering showed that the best 5 features were MntFruits, MntMeatProducts, MntFishProducts, MntSweetProducts, and Response, with a total of 3 clusters and a 0.593 silhouette score. This was better than the first K-Means model, where feature selection was not applied, because the second model had less features and better Silhouette Score.
In contrast, the best 6 features, MntFruits, MntMeatProducts, MntFishProducts, MntSweetProducts, MntGoldProds, and Response, produced 5 clusters with a silhouette score of 0.522, which doesn’t meet the minimum silhouette score requirements and was worse than the model with the best 5 features. It means
DBSCAN was not used in this case due to the extensive time required for feature selection and hyperparameter tuning. Since the DBSCAN and K-Means models with the best 6 features were not used, the only remaining option is the K-Means model with the best 5 features.
Cluster Visualization
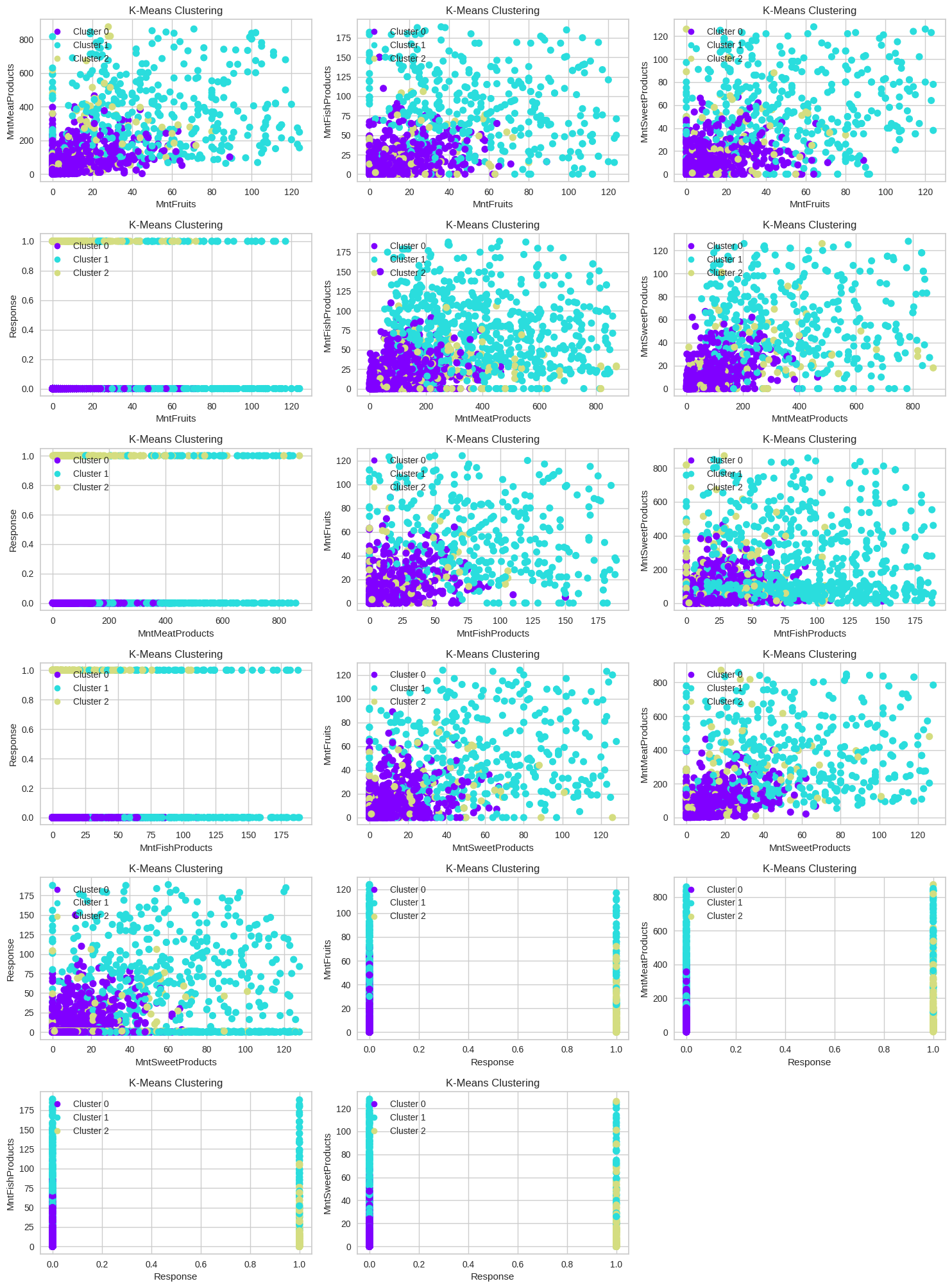
The K-Means with best 5 features was visualized with matplotlib. Here is the visualization:
Cluster Interpretation
Here is the conclusion of the cluster interpretation. To see more detailed process of this part, visit the google colab link: Machine Learing for Clustering
Features:
- MntFruits: Amount spent on fruits in the last 2 years
- MntMeatProducts: Amount spent on meat in the last 2 years
- MntFishProducts: Amount spent on fish in the last 2 years
- MntSweetProducts: Amount spent on sweets in the last 2 years
- Response: 1 if the customer accepted the offer in the last campaign, 0 otherwise
Cluster 0:
- Customers in Cluster 0 have moderate spending on fruits.
- Customers in Cluster 0 have moderate spending on meat products.
- Customers in Cluster 0 have low spending on fish products.
- Customers in Cluster 0 have moderate spending on sweet products.
- It can be interpreted that customers in Cluster 0 are more likely to respond with "False" for "Response."
Cluster 1:
- Customers in Cluster 1 have low spending on fruits.
- Customers in Cluster 1 have low spending on meat products.
- Customers in Cluster 1 have moderate spending on fish products.
- Customers in Cluster 1 have low spending on sweet products.
Cluster 2:
- Customers in Cluster 2 have high spending on fruits.
- Customers in Cluster 2 have high spending on meat products.
- Customers in Cluster 2 have high spending on fish products.
- Customers in Cluster 2 have high spending on sweet products.
- It can be interpreted that customers in Cluster 2 are more likely to respond with "True" for "Response."



